Projects
1. LLM Serving Systems
This project targets the fundamental challenges of building highly efficient, scalable, and cost-effective LLM serving systems. As illustrated in the figure, we introduce key innovations across every layer of the serving stack.
Distributed Request Router: At the top of the stack, our intelligent router manages incoming traffic. Going beyond simple load balancing, our work, DualMap (ICLR’26) achieves both cache affinity and load balance for distributed LLM serving. It ensures that requests are routed not only to available instances but preferentially to those that may already have the required context cached, significantly reducing redundant prefill computation.
Disaggregated LLM Serving: At the core of the system, we decouple the computationally distinct phases of LLM inference—prompt processing (Prefill Instance) and token generation (Decode Instance). This fundamental separation is orchestrated by system-wide optimizations such as Adrenaline (ArXiv’25), which disaggregates and offloads memory-bound decode-phase attention to compute-bound prefill instances, and TaiChi (AiXiv’25), which unifies PD aggregation and disaggregation under a new serving architecture. To further accelerate the memory-bound decode phase, we propose a new dynamic sparse attention algorithm (PSA@ArXiv’25) and SparseServe (ICS’26), a long-context LLM serving system that unlocks the parallel potential of DSA through efficient hierarchical HBM-DRAM management.
Context Caching: Underpinning the stack is a robust caching layer. Our foundational work, CachedAttention (USENIX ATC’24), is the first context caching system to leverage hierarchical storage (e.g., DRAM and SSDs). This enables efficient management of massive KV caches for long-context handling and high-throughput serving.
Together, these layers form a comprehensive, principled solution that addresses the primary bottlenecks in modern LLM serving, paving the way for more powerful and accessible AI services.
2. Agents
This project tackles the central challenges in building advanced autonomous LLM agents. As shown in the figure, the core architecture is organized around an Agent Brain, which serves as the cognitive hub for decision-making. The agent functions in a continuous loop: the Perception module processes observations from the Environment, the Planning module formulates an Action, and the action in turn alters the environment, producing new observations, reward signals, feedback, and opportunities to invoke external tools. This creates an adaptive learning cycle. By integrating advances in reasoning and memory, our project aims to develop agents that are more capable, efficient, and intelligent. We currently focus on two key components of the Agent Brain:
Planning (LLM): At the core of reasoning is a large language model dedicated to planning. Our main contribution here is a novel approach to Accelerating Tree of Thoughts (ToT) Reasoning, currently under review. This method enables efficient exploration of multiple solution paths, significantly strengthening the agent’s problem-solving capacity and decision robustness.
Memory: To provide long-term learning and context retention, the agent includes a dedicated Memory module. We have designed an Efficient Agent Memory System, also under review, that supports accurate, low-latency storage and retrieval of relevant information, ensuring continuity and coherence across extended interactions.
3. Disaggregated Memory Infrastructure
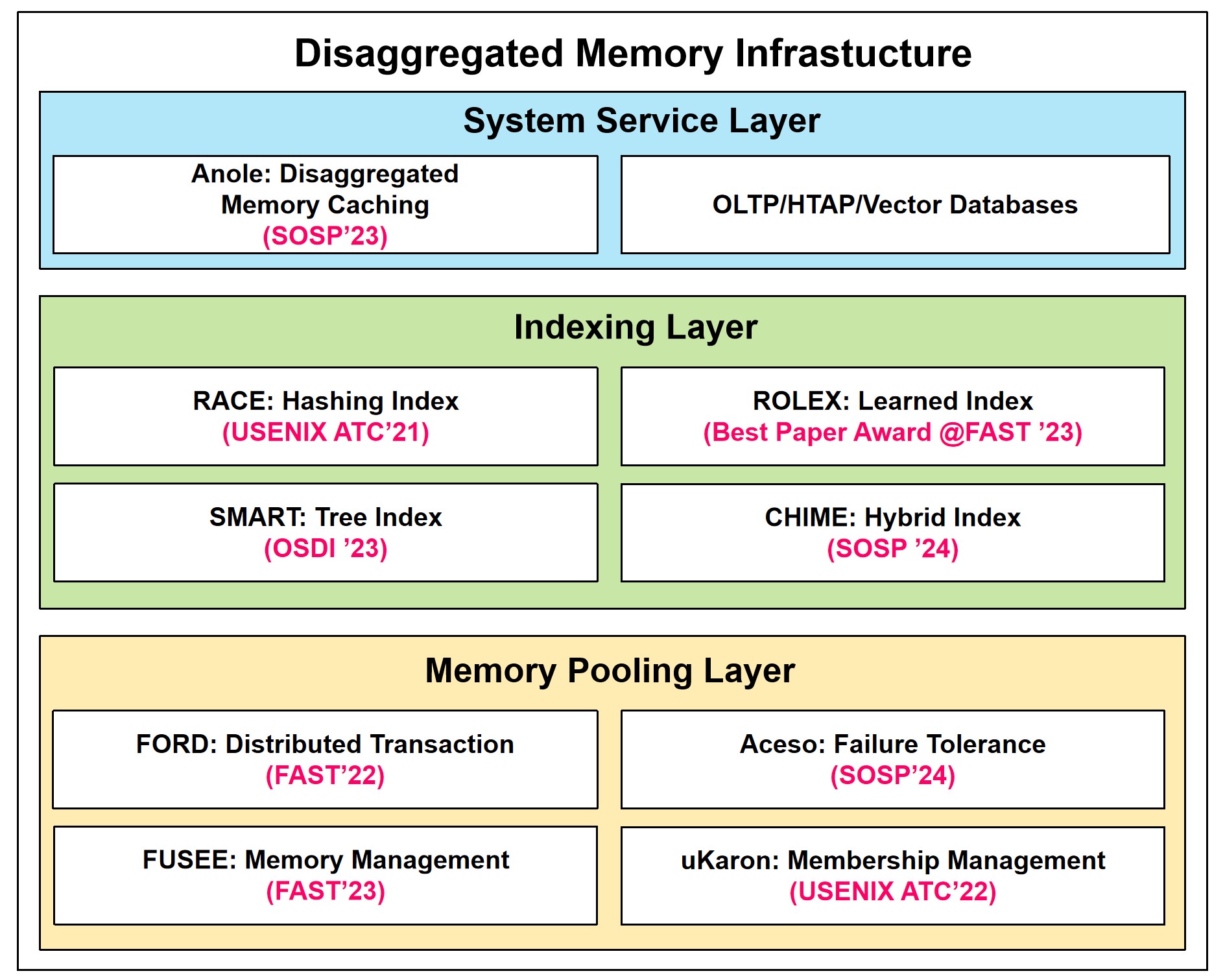
This project aims to build a robust and high-performance infrastructure for disaggregated memory, enabling applications to efficiently access large, distributed memory pools as a unified resource. By decoupling memory from compute, our architecture offers significant improvements in resource utilization, scalability, and cost-efficiency for data-intensive services. The infrastructure is designed as a three-layer stack, with foundational research contributions at each level.
Memory Pooling Layer (Foundation): At the bottom layer, we address the core challenges of creating a scalable and reliable memory pool from distributed machines. Our work in this area includes foundational techniques for distributed transactions (FORD@FAST’22), efficient memory management (FUSEE@FAST’23), robust failure tolerance (Aceso@SOSP’24), and scalable cluster membership management (uKaron@USENIX ATC’22). These components provide the fundamental building blocks for a scalable disaggregated memory pool.
Indexing Layer (Data Access): Built on top of the memory pool, the indexing layer provides scalable and high-performance mechanisms for organizing and accessing data. We have explored a diverse range of indexing strategies to suit different data structures and access patterns, including hashing (RACE@USENIX ATC’21), tree-based (SMART@OSDI’23), learned (ROLEX, Best Paper@FAST ‘23), and hybrid (CHIME@SOSP’24) indexes. This layer ensures that applications can retrieve data from the vast memory pool with low latency.
System Service Layer (Application): The top layer exposes the capabilities of the disaggregated memory infrastructure to applications. Our key service is Ditto (SOSP’23), a disaggregated memory caching system that provides a powerful caching solution for applications. This layer also directly supports demanding workloads such as OLTP, HTAP, and vector databases, allowing them to leverage the full benefits of a large, fast, and disaggregated memory pool.
Together, these layers form a complete and principled solution for building next-generation disaggregated datacenter infrastructure, enabling more efficient and powerful data-intensive applications.
4. Persistent Memory Systems and Architectures
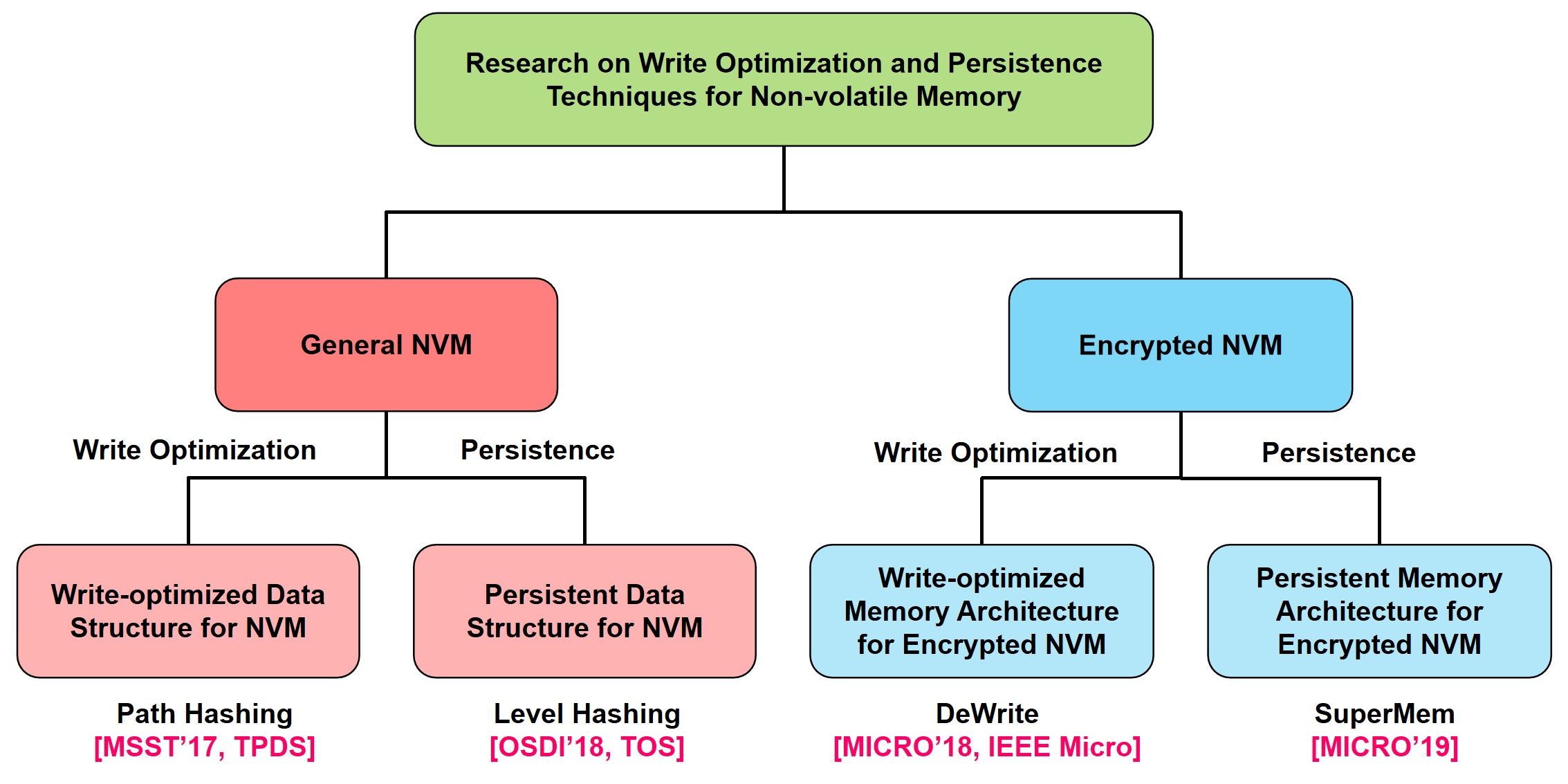
With the increasing number of processor cores and the emergence of data-intensive applications, the demand for large-capacity main memory is growing. While DRAM is the primary main memory, its scalability and energy efficiency limit further capacity expansion. Non-volatile memory (NVM), with high scalability and energy efficiency, is a promising next-generation main memory. However, modern computer systems are optimized for DRAM, so adopting NVM introduces challenges in write endurance, data persistence, and security. NVM cells have limited write endurance, data must be persisted to guarantee crash consistency, and retaining data after power-off raises security concerns for edge devices. This dissertation addresses these challenges and proposes efficient solutions for both general and encrypted NVMs.
For general NVM, this dissertation proposes two hash-based structures. 1) Path Hashing (MSST’17): A write-optimized hash index that leverages position sharing, double-path hashing, and path shortening to eliminate extra writes while achieving high space utilization (up to 95%) and low latency. 2) Level Hashing (OSDI’18): A persistent hash index that guarantees crash consistency with log-free schemes and efficient in-place resizing, achieving 1.4–3× speedup in insertions, 1.2–2.1× in updates, and over 4.3× in resizing compared to state-of-the-art methods.
For encrypted NVM, this dissertation proposes two architectures. 1) DeWrite (MICRO’18): A write-optimized memory system that combines lightweight cache-line deduplication with opportunistic parallel encryption, reducing writes by 54%, accelerating reads/writes by 3.1–4.2×, and lowering energy consumption by 40%. 2) SuperMem (MICRO’19): A persistent secure NVM architecture using a write-through counter cache, locality-aware counter write coalescing (CWC), and cross-bank counter storage (XBank) to guarantee consistency while improving performance; CWC reduces up to 50% of writes, and XBank achieves up to 2× speedup.
These contributions collectively enhance the endurance, performance, crash consistency, and security of both un-encrypted and encrypted NVMs.